Simon Jenni Givi Meishvili Paolo Favaro
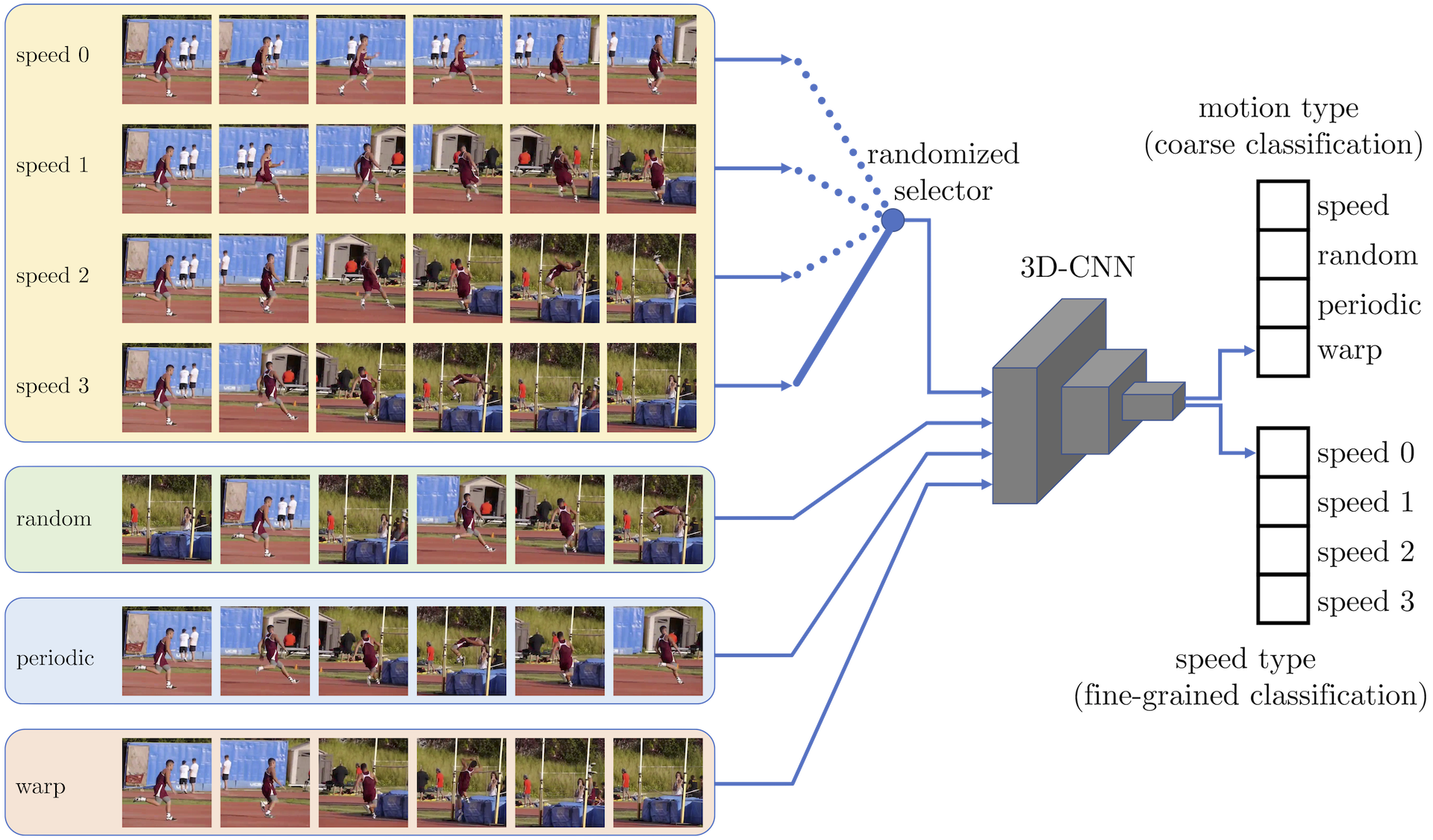
Training a 3D-CNN to distinguish temporal transformations. In each mini-batch we select a video speed (out of 4 possible choices), i.e., how many frames are skipped in the original video. Then, the 3D-CNN receives as input mini-batch a mixture of 4 possible transformed sequences. One is the original sequence at the selected speed (speed 3 in the illustration). Another one is a random permutation of the sequence; a third one is obtained by substituting the second half of the sequence with the first in inverted order and also with different frames to avoid symmetries; the fourth one is obtained by sampling the frames around those of the chosen speed.
Abstract
We introduce a novel self-supervised learning approach to learn representations of videos that are responsive to changes in the motion dynamics. Our representations can be learned from data without human annotation and provide a substantial boost to the training of neural networks on small labeled data sets for tasks such as action recognition, which require to accurately distinguish the motion of objects. We promote an accurate learning of motion without human annotation by training a neural network to discriminate a video sequence from its temporally transformed versions. To learn to distinguish non-trivial motions, the design of the transformations is based on two principles: 1) To define clusters of motions based on time warps of different magnitude; 2) To ensure that the discrimination is feasible only by observing and analyzing as many image frames as possible. Thus, we introduce the following transformations: forward-backward playback, random frame skipping, and uniform frame skipping. Our experiments show that networks trained with the proposed method yield representations with improved transfer performance for action recognition on UCF101 and HMDB51.